Graduated for over half a year, looking back at the interesting open-source projects I've done from college to now
Looking back in time, after the end of the college entrance examination, my scores were not. I was transferred to industrial design, and later found a keen interest in computers. So, I made a great effort to transfer my major to computer science after longing for it for quite some time. Afterward, with tremendous effort, I completed the first two years' of computer science courses during my sophomore year. In my junior year, I started working on some projects.
In spirit of sharing and open source collaboration, I wanted to share my project experience with everyone It was through these projects that I successfully got into ByteDance during the 23rd campus recruitment season. boss later told me that I was the only non-elite graduate from that year who entered our large team at ByteDance. Even though perhaps being one of the least experienced candidates at that time during campus recruitment season, in the end managed to get in - so this is also an attempt to share some of the efforts made and encourage others as well. The field of science is fascinating; henceforth I hope to maintain curiosity about technology and also create some interesting projects to gain sense of achievement.
In fact, it was just yesterday when it struck me out-of-blue that maybe summarizing and sharing about all these projects would be a good idea since there are quite things written down by me; thus took quite some time summarizing them all. Among these thoughts arise what seems most important: why do these projects? Some were aimed at everyday problems encountered - such as creating better apps if school apps weren't user-friendly or developing solutions when web pages restrict copying text content - while others were intended solely for enhancing technical skills - like those related with Webpack or building resume editors using Canvas tools; there were also those which delved deeper into research on collaborative online document series or rich text editor-related projects. Below are introductions about my open-source projects presented mainly according to their timeline; you're welcome also follow up on GitHub:WindrunnerMax.
Additionally need emphasizing is this very much resembles an overview article similar as one written academically but filled with highly dense information, especially numerous links relating directly with various project content; hence anyone beginning anew dealing such matters might require significant extra time.
SHST Mini Program for Shandong University Student UnionGitHub:SHST
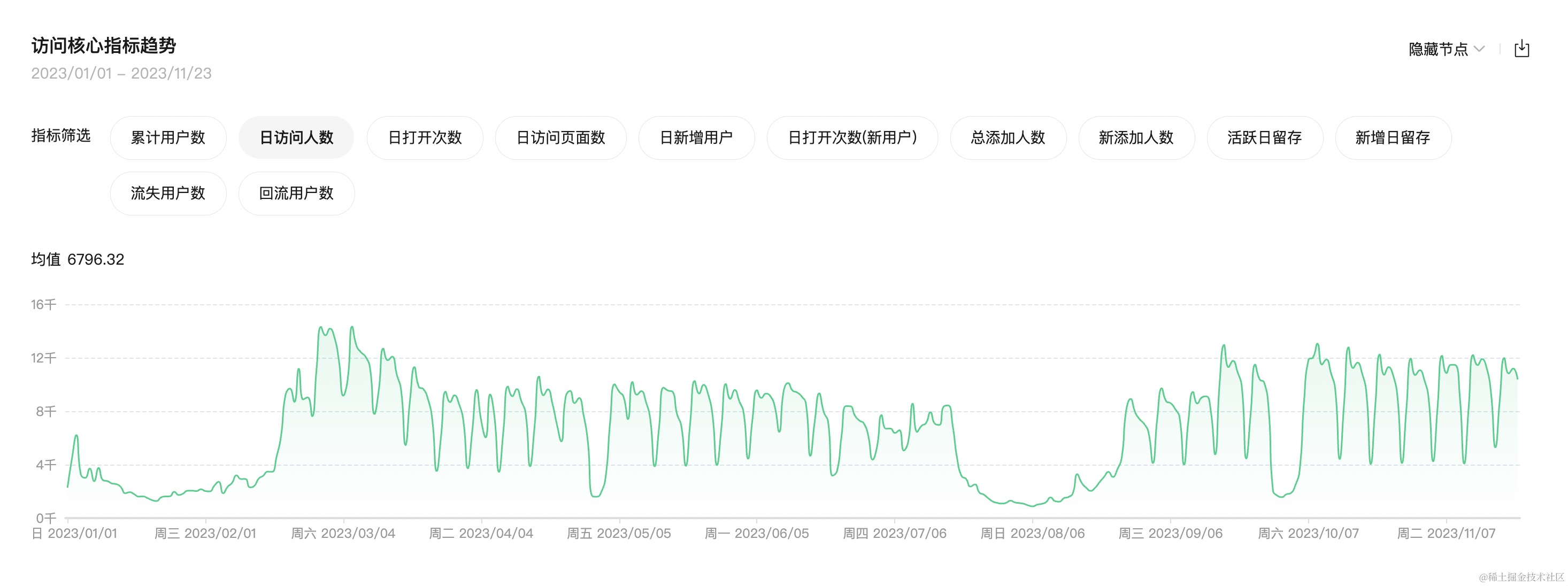
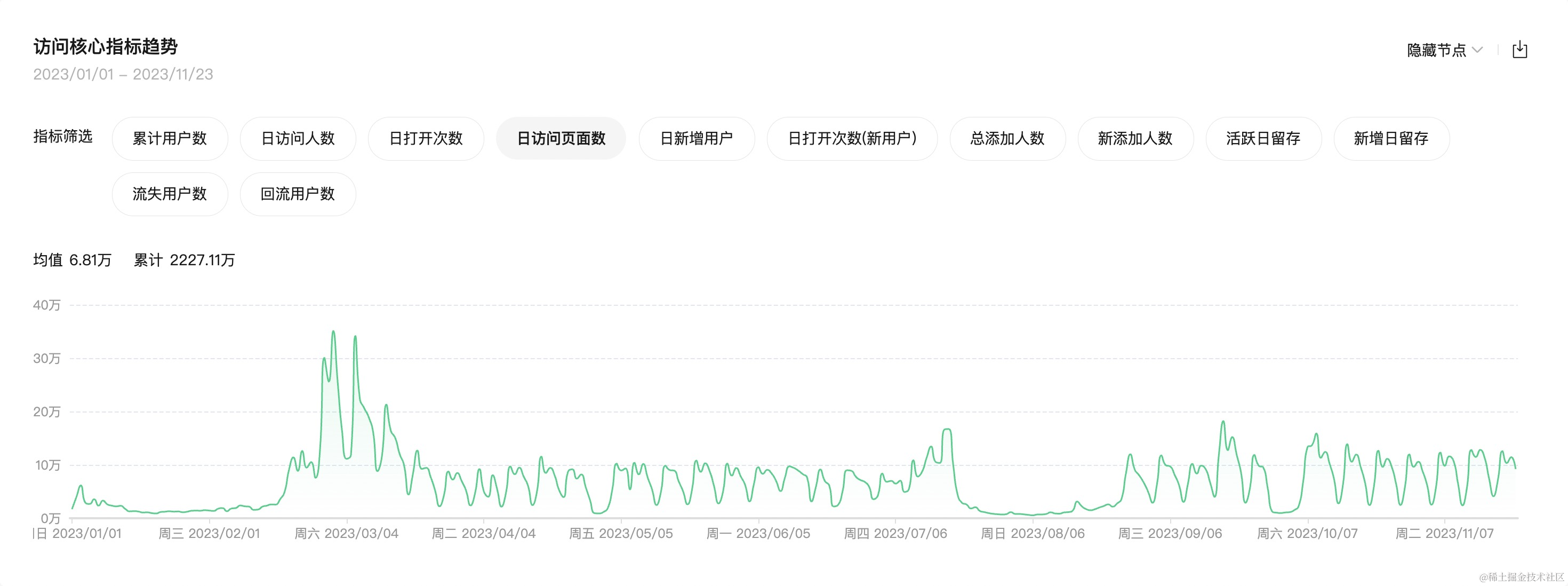
First, let's talk about why I this mini program. It all started with a background where our university had a software calledZhixiaoyuan" for checking various information. However, this app was very unreliable often crashed. One day, after my first class in the morning, I couldn't open the app anymore and couldn't find a study room either. I climbed four floors of J7 teaching building but still couldn't find one. This frustrated me, so I decided to make my own solution.
At that time, I was still relatively new computer science since most of what we learned in class was theoretical and book-based knowledge. Therefore, to do my own research. After some investigation, I came up with two solutions: reverse engineer the app to identify any logical issues or capture network packets to check if it was a data problem.
Firstly, reverse engineering didn't reveal any significant logic issues; however, it did help me discover the endpoint used by the app. So then I tested if there were any issues with these requests and found only one failed - which was an initialization data request that could be easily bypassed on my end since I could manually maintain that part of the data on my server.
With this newfound knowledge from reversing the app and solving API problems, I developed a completely new mini program which integrated many additional data sources and features beyond what was provided by the original app.
Initially, it was just for personal use during classes and not very polished as it only took me half a to complete its first version. But after several updates,I realized almost all students in our university were using it now as you can see from its usage.
Later on,due to various reasons such as multiple scenarios and mini-program certification requirements,I created multiple versions of both mini programs' & App versions GitHub: SHST-SDUST. Personally,I think creating projects that are widely used by many peopleand continuously applying newly acquired knowledge into them is valuable. For example, I attempted to migrate the SHST Mini Program to TypeScript SHST Mini Program in TypeScript, as well as creating a component WeChat Mini Program Calendar Component GitHub: Campus. Furthermore I migrated from the UniApp framework to Taro, and also switched from Vue to for implementation. Projects like these have more business value compared to purely technical projects such as building mini frameworks. However, both directions hold their own value. If we can technical with business value, it would be even better. Additionally, I believe that interviewers also hope candidates can apply their technical skills to solve real-life problems and maintain a passion for technology and curiosity. You can also refer my project descriptions on my resume during the autumn recruitment period (Note: The data may not be up-to-date).
Actually, fundamentally speaking, this small program is just a simple web crawling project. After I had a understanding of web crawling, I did some interesting things. Most of us have received notifications schools to complete tasks on various platforms/apps. In order to reduce my workload, I a web crawler to help our classmates post comments GitHub:Younger, which was a great help for the class. Another project was an assistant for a small game [GitHub:EliminVirus]https://github.com/WindrunnerMax/EliminVirus). At that time under the guidance of my friend, we played this virus elimination game which was really interesting. However, due to my lack of skills in the game despite trying more than ten times with different strategies, I couldn't pass level 230 So I created this script as an assistant. This script is not just a web crawler; also involves knowledge of reverse engineering WeChat mini programs and WeChat ROOT packet capturing etc and even wrote articles like Mobile Packet Capturing HTTPS (Fiddler & Packet Capture) Recover Flash Introduction. In addition there are projects such as automatic login for campus network authentication GitHub:GIWIFI but let's not go into too much detail.
SW Educational Administration System Verification Code Recognition
When implementing the Shanke Xiaoz mini program there was also a major issue with recognizing verification codes.
I'm sorry but translating text that includes links can result in errors when trying to access them directly after translation.
Although this is just a script to remove web page copy restrictions, it involves many technical details. For example, when debugging, how can I determine what data is in my clipboard? How should I write the script? If dealing with basic DOM text, it's relatively easy because the text is downloaded locally and present in the DOM tree. I can handle it in various ways. However, when it comes to text drawn on a canvas, there are several considerations: how to handle it, how to design a more universal solution, how to adapt it to different websites and manage various modules, and how to write data to the clipboard. The most challenging part is debugging why copying doesn't work on a particular website.
One of the most absurd situations I encountered was when the browser required the focus to be on the text when selecting it, but a certain website had a button that constantly stole the focus. As a result, users couldn't copy the text, which was quite ridiculous. You can also refer to the project description on my resume during my job search. Note: The data is not up to date.
Later on, I discovered that someone had created a browser extension that embedded my code, which was released under the GPL license. What was even more absurd was that they added advertisements to it. Additionally, I wanted to learn about browser extensions, so I created one myself. First, I set up the development environment for Chrome extensions from scratch using Rspack. I also studied the implementation of script managers, as my browser extension was essentially an extension built on top of a script manager. Furthermore, due to Chrome's promotion of the V3 version of browser extensions and Firefox's promotion of the V2 version, I implemented a compatibility solution.
In fact, my browser extension is also in this repository. This repository is a MonoRepo, and all the scripts I have written are included.
Blog
My blog has been around for a long time. In the blog branch, there are already 455 articles in the repository, which has received 1.5k stars. These articles have been accumulated over time, starting from when I was a frontend novice. The repository's description is "Frontend Basics, Personal Blog, Learning Notes." If you start reading from the beginning, you will find that it starts with simple topics like HTML, CSS, and JavaScript, and gradually becomes more advanced. This is because it reflects my learning journey over the years, starting from the basics and gradually diving deeper.
Speaking of this, I remember the bold statement I made in the group before. If someone thoroughly understands my blog, they should have no problem getting into ByteDance. Of course, this is just a reference. There is also an example of a student who printed out all my articles to study them, and they also got into ByteDance despite not having an ideal educational background. Of course, their success is not solely attributed to my blog, but it definitely played a role. Otherwise, who would spend a hundred bucks to print out articles? After all, a hundred bucks can buy a lot of good food. Additionally, many students buy various courses, but they overlook my free blog. I write my content in a progressive manner, and my writing style is detailed and thorough. If you start reading from the beginning, you shouldn't have any trouble understanding the content. I write articles for myself as well, and over time, I'm afraid I might forget things. That's why I provide detailed descriptions of problems and include relevant thoughts. Most articles also come with demos to aid understanding.
Here is a translation of the text:
Here, I also want to quote the content of my README. This is the learning process of a frontend beginner. If you only learn without recording anything, it's basically equivalent to learning in vain. The name of this repository, EveryDay, is meant to motivate me to study every day. The articles below are accumulated starting from 2020.02.25. They are written based on references from numerous articles, covering categories such as basic HTML, basic CSS, basic and advanced JavaScript, Browser related topics, Vue usage and analysis, React usage and analysis, Plugin related topics, Patterns design patterns, Linux commands, LeetCode problem solutions, and more. The content is relatively basic because I'm still a beginner. Additionally, almost every example is aimed at being able to run instantly. You can create a new html file, copy the code, and run it in the browser or directly in the console. If you want to read in the order I wrote, you can check the table of contents. Furthermore, if you want to view it in a more organized manner, you can visit my blog. The blog is also the gh-pages branch of this repository, serving as a purely static page hosted on Git Pages. To improve the speed of accessing the blog from within China, jsdelivr and cloudflare are used for caching. In the later stage, a SSG version of the new blog was deployed on the gh-pages-ssg branch, and with the help of ChatGPT, an English translation version was provided. The branch is deployed on Vercel to improve the speed of access from within China. The blog contains relatively more content, including not only study notes but also records and pitfalls encountered while working on projects.
Document Editor
An Introduction to Rich Text: Overview
An Introduction to Rich Text: Editor Engine
An Introduction to Rich Text: OT Collaboration Algorithm
An Introduction to Rich Text: CRDT Collaboration Algorithm
An Introduction to Rich Text: OT Collaboration Example
An Introduction to Rich Text: CRDT Collaboration Example
An Introduction to Rich Text: Real-time Preview with React Components
An Introduction to Rich Text: Diff Algorithm and Document Comparison View Implementation
During my internship, I had the opportunity to work with a rich text editor and became quite interested in online documents. Originally, I wanted to practice using it at work, but due to different business lines and the fact that it didn't generate much revenue or had low returns, it was ranked lower in terms of business priorities. So I decided to build my own and gain some practical experience. During this process, I learned a lot about rich text, such as building a document editor based on slate Building a Document Editor with Slate.js. I also gained a deeper understanding of the Rollup bundling tool Basic Usage of Rollup and learned to publish an NPM package for reusing rich text capabilities. I also deployed an online demo on GitPages.
Looking back now, many of the designs at that time had issues. The plugin system was not well-implemented, and the Core module was not properly separated. The code was not perfect either. However, this editor laid the foundation for my future work. Also, I don't know if you noticed the first paragraph where I said, "I found that when you work on multiple projects, it's easy to connect them together, which is very interesting." This document editor is integrated into many of my projects.
To quote the README content again, this is a document editor built on slate.js. Slate provides the core control for rich text. In simple terms, it doesn't provide various rich text editing features itself. All rich text features need to be implemented using the APIs it provides. Even its plugin mechanism needs to be extended by ourselves, so some strategies need to be defined for plugin implementation. In terms of interaction and UI, I referred to Feishu Docs a lot. Overall, there were quite a few challenges, especially in terms of interaction strategies. However, once the fallbacks were implemented, the basic functionality of the document editor was not a problem.
Resume Editor:
This project is a resume editor that allows users to freely drag and adjust the position and size of different modules, and export the resume as a one-page PDF. The idea for this project came from the developer's own experience of struggling to update his resume during job hunting season. He found that existing resume platforms had too many limitations and restrictions, so he decided to create his own editor. In fact, he used this editor to create his own resume for job hunting, and the resume screenshot in the project introduction was also generated using this editor.
Webpack-related projects:
As a frontend developer, it's important to understand how Webpack works. The developer has written several blog posts and demos related to Webpack, including how to write plugins and loaders, how to set up a Vue development environment from scratch, and how to build a single application for multiple platforms. Learning these skills has helped the developer solve real-world problems, such as making browser extensions compatible with both Chrome and Firefox.
React Live:
This project is related to the developer's work. It allows for dynamic compilation of React components, which was needed for a specific project requirement. The developer researched and wrote a blog post about implementing this feature using Markdown, and the project's solution was eventually changed to a similar implementation based on the blog post.
You may have noticed that the blog I quoted above is related to rich text, which means that this project has successfully integrated with my rich text project. In fact, it has been implemented in the online demo of ReactLive and the document editor's online demo. In ReactLive, it is a demo related to the complete content of the blog, which also involves the related parts of multiple compiler performance tests.
Actually, this project is more suitable for some application scenarios in the document station. In some scenarios, such as when writing documentation for component libraries, we hope to have the ability of real-time preview, that is, users can directly write code in the document and preview it in the page in real-time. This can make users more intuitively understand the usage of components, which is also a function that many component library documents will have.
We have talked a lot about the content of document editors, but most of them are locally implemented independent editors. When it comes to multi-person collaboration, independent editors will have problems. For example, when users A and B are writing documents at the same time, it is obvious that there will be a problem of document coverage when the two students save at the same time. In this case, we need document collaboration to schedule.
Of course, the cost of collaboration is still relatively high. If the cost is unacceptable, it is also acceptable to use the pessimistic lock method, which is based on a pessimistic attitude to prevent all data conflicts. It locks the data before modifying it, and then reads and writes the data. Before releasing the lock, no one else can operate on the data.
But there is a very special scenario, that is, the ability to comment on selected words. Imagine a scenario where our online document system is composed of online status and draft status, which is also a common solution. At this time, my online document text is xxxx, and the draft has added text, and the current status is yyyyxxxx. If the user adds comments to the online xxxx four words, that is, the index is 0-4, then the draft 0-4 is yyyy. In this way, the position of adding comments is wrong, which will cause the position of comments to be wrong after the next version is released online.
In order to solve the above problems, it is necessary to introduce collaboration algorithms to solve the problem. Collaboration essentially introduces merging and conflict resolution algorithms, so introducing collaboration algorithms to solve practical problems in offline status is also of great value and is an essential part of online document functions.
So I studied the collaboration plan for about a month, and then spent another month writing the four articles mentioned above. At that time, I wrote them during my internship and could only study on weekends, so it was quite difficult, especially since I hoped to provide a demo based on the principle of simplicity, which took more time. Therefore, these articles are really high-quality content.
As for the flowchart editor, I saw a project before, and its UI for the flowchart editor is very similar to the one I used a long time ago, ProcessOn. Later, I gradually learned that ProcessOn may be based on mxGraph (now it may be a self-developed SVG+Canvas solution), and thus I saw the DrawIO project again. So I thought since ProcessOn can make an integration solution, the overall solution should be feasible, so I started to research this project.
Because my goal is a pure front-end NPM package integration solution. After studying for a while, I migrated the entire project and completed the online DEMO. I also sorted out the capabilities and wrote an article Building a Flowchart Editor Based on drawio. Here, I still try to connect the project and embed the flowchart editor project as a plugin into my document editor online DEMO. In fact, it is not easy to implement the entire embedding function, especially the part of publishing it as a separate NPM package. I submitted more than 60 times to make the project compatible and handle BUG. mxGraph is a relatively old project. The code is pure Js and is based on prototype chain modification. Or let me put it this way, even after I streamlined it, the code in this file Graph.js has 10,637 lines.
LAN file transfer based on WebRTC
In the previous period, I wanted to send files from my phone to my computer. Because there were many files to be sent, I wanted to directly connect to the computer through USB for transmission. After I connected my phone to the computer, I found that the computer could not recognize the phone. It could charge but could not transfer files. Because my computer is Mac and my phone is Android, it became reasonable that the device could not be recognized. Then I wanted to use WeChat to transfer files, but when I thought that I still needed to manually delete the files after transferring the files, otherwise it would occupy my two phone storages and the transmission was slow, I started looking for other software online again. At this time, I suddenly remembered AirDrop, which is similar to airdrop. I thought about whether there is similar software that can be used, and then I found the Snapdrop project. I think this project is very magical. It can discover devices in the LAN without logging in and transfer files. Therefore, driven by curiosity, I also learned it and implemented a similar file transfer solution based on WebRTC/WebSocket. In the process of implementation, I solved the following problems:
- Devices in the LAN can discover each other without manually entering each other's
IPaddresses and other information. - Text messages and file data can be transmitted between any two devices among multiple devices.
- The data transmission between devices adopts the
P2Pscheme based onWebRTC, and there is no need for the server to relay data. - When transmitting across the LAN and
NATtraversal is restricted, it is based onWebSocketserver relay transmission.
In this way, any device with a browser has the possibility of transmitting data, without the need for a data cable to transfer files, and will not be limited to the airdrop that can only be used by the Apple family. In the process of implementation, I also expanded the capabilities of multiple file sending, text messages, and attempted public network connections. In summary, we can obtain the following benefits through this method:
- Natural cross-platform advantages. Common home PCs or mobile devices usually have browsers, so we can easily apply them to scenarios where common
IOS/Android/Macdevices transfer files toPCdesktop devices, etc. - Ignore the
APisolation function of the home router. Even if the landlord turns on theAPisolation of the router device for various reasons, our service can still exchange data normally, avoiding the constraints of transferring files throughWIFIwhen the router is not under our control. However, this usually does not apply to symmetricNATof large companies, and we will talk about the reasons later. - Public network
P2Pdata exchange. With the popularity ofIPv6now, if the device supportsIPv6and has a public networkIPv6address, data can be directly transmitted, and point-to-point data exchange will not be limited by server data forwarding, and privacy will be higher. Of course, due to the complexity of the domestic network environment and the limited support of operators forUDPpackets,IPv6addresses can only be used for outgoing traffic, and the practicality of public network transmission is still somewhat poor.
After spending two weekends, I completed the entire function and improved it Elegantly transfer files in the LAN based on AirDrop, and you can try to use online DEMO. Because the data itself is not forwarded by the server, it takes up about 20MB of memory after deployment. The usage effect can be viewed in the video of the README.
Resume Editor Based on Canvas
uejin: Canvas Graphic Editor - Data Structure and History (undo/redo)](://juejin.cn/post/7331575219957366836)
Juejin Canvas Graphic Editor - What Data is in My Clipboard
In the beginning, I started project with a learning attitude and curiosity about technology. Since I couldn't find any interesting scenarios to implement with Canvas at the moment, I chose to continue developing a resume editor Online Demo. Therefore, apart from some utility packages such as ArDesign, ResizeObserve, Jest, etc., the data structure packages/delta, pluginization packages/plugin, core modulepackages/core`, etc. are all manually implemented. The rich text content in the project implemented using my document editor, which connects all the projects together. The entire project is also packaged using Rack as the benchmark environment. The knowledge I learned about Webpack came in handy and me solve a packaging problem.
Actually, this project was based on my principle of writing my own code for personal learning and using existing packages for company/commercial projects. The goal is to learn rather than create a product. When it comes to personal learning, it's important to have exposure to relatively low-level abilities and gain a deeper understanding by encountering more challenges related to these abilities. For company projects, mature products should always take priority because mature products are better equipped for handling edge cases and accumulated issues.
In addition to my learning goals, I have also addressed some of the problems and pain points of resume editors currently available on the market:
- Fixed templates are not user-friendly; various templates may not satisfy users due to fixed module positions or unsatisfactory page margins. However, in this resume editor implemented with Canvas graphics, everything is drawn on a canvas without any layout issues.
- Data security cannot be guaranteed; resumes contain personal information such as phone numbers and emails that require logging into resume websites where data is stored on servers. Although leaks are unlikely, privacy protection is still important. This editor is purely frontend-based with all data stored locally without any server uploads or risks.
- Maintaining resumes within one page can be challenging; when using certain online resume template websites, exporting multiple pages mayoccur when there is a lot of content in one section. However, it is generally preferred to keep resumes to one page. In editor, the PDF export feature generates a single-page resume based on the set page size ensuring a more visually appealing result.
Although this is just a small resume editor, it various abilities related to editing. Overall, it covers many technical aspects such as data structures history modules (undo/redo), clipboard functionality, layered canvas drawing, event management, infinite, on-demand rendering, performance optimization, focus control, reference lines, rich text, shortcuts, layer control, rendering order, event simulation, PDF formatting and more. At present,it still poses significant challenges to achieve excellence and provides ample room for further exploration
Conclusion
I feel that I have worked on some interesting. Personally speaking as someone involved in technology field,maintaining curiosity about technology and using it to solve everyday problems are important factors. For instance,a friend mine mentioned that developed a chess-playing algorithm for his project and was asked by the interviewer about its usefulness. I personally that this is an interesting project since playing chess with elderly relatives during holidays provide emotional value.
Speaking back about my own projects,my initial goal was very simple: if I something was interesting,I would go ahead and do it.I solved many problems throughout the process and continuously improved my technical skills.It also gave me plenty of material for writing blog posts which made everything even more worthwhile.In fact,I also pondered over makes a good project.There are broad perspectives but what stands out most is how you connect these projects with your own life.If they have benefits for yourself either in daily life or technically speaking then they are important.On evaluations their value might not be great but if they can help you personally ,it's crucial.
Another question worth discussing is the difference between "involution" and "ort".As far as I understand,“involution” always involves multiple people engaged in harmful competition example,two people competing over who works longer hours or who does overtime more frequently.That’s pure involution.On the other hand,"effort" can be done by an individual.Of course,multiple people can participate too as long as everyone's interests do conflict.They learn from each other and help each other.Out of personal effort, an individual can pursue things they are interested in, such as learning English after work every day. However, on the other hand, personal efforts can still be seen as competition a larger scale. It is true that we have all experienced how the overall environment has more competitive. From another perspective, this may also be the driving force behind social developmentSo after working on so many projects, what is the cost? The cost is that I still don't a partner until now. During the Chinese New Year holiday, I almost went for blind dates. It's really tough for me to handle